Ontem eu li o README de um projeto novo chamado Rampart e o número que me fez parar não foi o hype. Foi este: 14,7 MB , 98,42% de recall em 30 mil exemplos e tudo rodando no navegador. Esse assunto importa porque muita empresa já usa IA com texto real de cliente.
Ontem eu li o README de um projeto novo chamado Rampart e o número que me fez parar não foi o hype. Foi este: 14,7 MB, 98,42% de recall em 30 mil exemplos e tudo rodando no navegador.
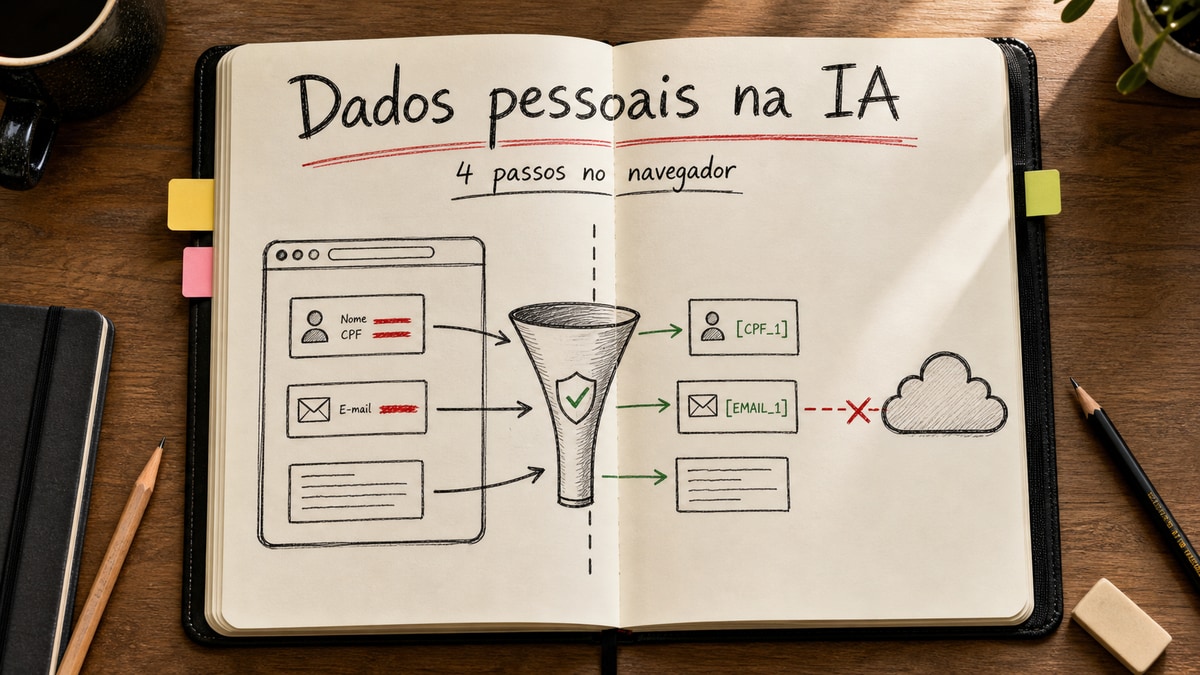
Esse assunto importa porque muita empresa já usa IA com texto real de cliente. Suporte cola ticket. Comercial cola email. Jurídico cola contrato. A promessa é produtividade. O risco é mandar dado pessoal para a nuvem sem perceber. Belo ganho. Belo processo. Belo problema.
Neste artigo eu vou te mostrar um jeito simples de reduzir esse risco hoje, sem teatro técnico. Eu uso o método T.E.L.A. para decidir o que sai do navegador, o que vira placeholder e como provar que o filtro não está dormindo no ponto.
Eu explico o problema em português claro.
Eu mostro o método T.E.L.A. em 4 passos.
Eu deixo um teste prático para você rodar ainda hoje.
O problema
Quando alguém fala "vamos colocar IA no atendimento", eu não penso primeiro no modelo. Eu penso no que o time vai colar dentro dele.
Se o prompt recebe nome completo, CPF, email, telefone, número de conta e endereço, você já criou um risco operacional. Não importa se o texto ficou bonito. O dado saiu.
Foi por isso que eu achei o Rampart interessante. O projeto foi anunciado no X e a equipe abriu o código no GitHub com uma proposta bem direta: redigir dados pessoais antes que eles saiam do navegador. O pipeline troca o dado bruto por placeholders como [GIVEN_NAME_1] e [SSN_1], manda só a versão filtrada para o modelo e restaura a resposta no cliente.
O dado concreto do repositório é bom o bastante para eu levar a sério, mas não para desligar o cérebro. A equipe reporta 98,42% de recall para termos privados em um conjunto de 30 mil linhas, 97,73% de recall em português e latência de 3,9 ms p50 no navegador com WebGPU. Ao mesmo tempo, o próprio README avisa que isso é harm reduction, não blindagem perfeita. Em nomes escritos fora do alfabeto latino, o desempenho cai muito. Em testes hostis, a robustez ficou em 86,4%.
É aqui que muita empresa erra. Vê um número alto, compra a ideia e pula a parte chata. A parte chata é justamente a que protege sua operação.
O framework / método
Quando eu preciso decidir se um fluxo de IA pode tocar dado pessoal, eu uso o método T.E.L.A.. É simples porque risco bom é risco entendido.
1. Tirar o bruto
Primeiro eu listo o que nunca deveria sair do navegador em texto puro.
Normalmente entram nessa lista: nome completo, documento, email, telefone, conta bancária, endereço exato e qualquer referência que permita identificar uma pessoa sem esforço.
Se o seu time ainda não mapeou essa lista, ele vai improvisar. Improviso com IA costuma virar vazamento com cara de automação.
2. Etiquetar com placeholders
Depois eu troco o dado real por marcadores estáveis.
Maria Souza vira [NOME_1]. 21999999999 vira [TELEFONE_1]. 123.456.789-00 vira [CPF_1].
Esse passo parece bobo. Não é. Ele deixa o modelo trabalhar no contexto sem carregar o dado bruto. O Rampart faz isso com uma combinação de regras determinísticas e modelo leve. Na prática, essa mistura faz sentido. Regex puro perde contexto. Modelo puro inventa moda. Os dois juntos brigam menos.
3. Liberar só o contexto útil
Aqui eu corto a ansiedade do time que quer mandar tudo "porque vai que ajuda".
Nem todo contexto precisa subir. Cidade pode ajudar. Estado pode ajudar. Tipo de problema pode ajudar. Endereço completo quase nunca precisa. O próprio Rampart usa uma lógica parecida: por padrão, ele mantém contexto mais amplo e remove a linha exata do endereço.
Esse é o ponto em que eu separo produtividade de preguiça. Contexto útil é uma coisa. Excesso de dado é outra.
4. Auditar antes de escalar
Por fim, eu testo o filtro com casos reais do negócio.
Eu pegaria 10 prompts que já aparecem no suporte, no comercial e no jurídico. Depois eu rodaria o fluxo procurando três coisas:
dado pessoal que vazou;
contexto demais que não precisava subir;
contexto de menos que matou a resposta.
Sem esse teste, você não está implantando IA. Você está torcendo.
Como aplicar hoje
Se eu tivesse que começar agora, eu faria um piloto em uma única superfície. Nada de colocar isso na empresa inteira no primeiro dia. Eu escolheria um fluxo pequeno. Por exemplo: resumir tickets de suporte antes de mandar para o modelo.
O pacote mínimo é este:
um filtro local;
uma lista clara do que deve ser mascarado;
10 prompts reais para teste;
uma checagem humana no resultado final.
Se você quiser usar o exemplo aberto do Rampart, o repositório mostra este fluxo básico:
import { createGuard } from "@nationaldesignstudio/rampart"; const guard = await createGuard(); const safe = await guard.protect(userMessage);
const reply = await llm(safe.text);
const finalReply = guard.reveal(reply);A lógica é boa porque cabe na cabeça de um founder:
1. o usuário escreve; 2. o navegador limpa o que não deveria sair; 3. o modelo recebe só a versão filtrada; 4. a resposta volta com os valores restaurados no cliente.
Se eu estivesse desenhando esse piloto para uma empresa hoje, eu faria assim:
Passo 1: escolher um caso de uso pequeno
Eu começaria com suporte, FAQ interno ou triagem comercial.
Esses casos têm volume, repetição e pouco espaço para heroísmo técnico. Ótimo sinal.
Passo 2: definir o que sobe e o que não sobe
Eu abriria uma planilha simples com três colunas:
dado;
sobe para o modelo?;
motivo.
Se a equipe não consegue explicar o motivo, eu corto. Dado sem motivo costuma ser dado sobrando.
Passo 3: testar 10 prompts reais
Eu colocaria prompts com nome, CPF, email, telefone, CEP e endereço. Também colocaria variações com erro de digitação, abreviação e acento. Português de operação não vem arrumadinho. Se o seu teste só funciona em texto de apresentação, ele não serve.
Passo 4: medir antes de expandir
Eu mediria quatro números:
quantos dados vazaram;
quantas respostas perderam contexto útil;
quanto tempo o fluxo adicionou;
quantas revisões humanas ainda foram necessárias.
Se o vazamento continuar alto, eu não escalo. Se a resposta perder contexto demais, eu ajusto o keep-set. Se o time reclamar que ficou lento, eu comparo com o custo de um incidente. Essa conta costuma encerrar a reunião bem rápido.
Se você quiser aprofundar o lado de infraestrutura local, vale ler meu artigo sobre IA local e modelos open weights. Se o seu interesse está mais em desenho de fluxo, eu também recomendo o texto sobre o que são agentes de IA e o guia simples sobre banco vetorial.
Resultados esperados
Eu não venderia isso como bala de prata. Eu vendo como corte de risco.
O primeiro resultado esperado é bem objetivo: menos dado pessoal saindo do navegador em texto puro. Só isso já melhora muito a conversa entre produtividade e compliance.
O segundo resultado é organizacional. Quando eu obrigo o time a definir o que sobe e o que não sobe, a empresa para de tratar prompt como terra sem lei. Parece detalhe. Não é. Processo ruim com IA só acelera erro.
O terceiro resultado é melhor compra de tecnologia. Depois que eu meço vazamento, latência e perda de contexto, fica mais fácil decidir se você precisa de uma solução pronta, de um pacote open source ou de nada. Sim, "de nada" às vezes é a melhor resposta. Nem toda empresa precisa transformar o navegador em laboratório.
Eu espero ganho rápido em clareza. ROI vem depois. E vem melhor quando a casa já não está vazando pelo ralo.
Perguntas rápidas
Esse tipo de filtro substitui política de segurança?
Não. Eu vejo como uma camada. Ele reduz o que sai do navegador, mas não substitui revisão jurídica, política de acesso, logging bem configurado e regra de retenção.
Dá para usar em português?
Dá. O próprio README do Rampart reporta 97,73% de recall em português no conjunto divulgado. Ainda assim, eu testaria com texto real do seu time antes de confiar sorrindo.
Isso resolve tudo?
Não. O projeto deixa claro que é redução de dano. Em escrita fora do alfabeto latino e em casos hostis, o resultado piora. Achei honesto da parte deles. Melhor uma limitação dita do que uma promessa maquiada.
Eu preciso disso mesmo se uso modelo bom?
Se o seu time cola dado pessoal em prompt, eu acho que sim. Modelo bom não apaga processo ruim. Só responde mais rápido.
Qual é o piloto mais simples?
Eu começaria por resumo de ticket, triagem comercial ou resposta interna com FAQ. Fluxo curto, dado real e impacto fácil de medir.
Conclusão
Minha leitura do dia é simples: a próxima discussão séria sobre IA nas empresas não é só qual modelo usar. É qual dado merece sair do navegador.
Se eu fosse você, eu rodava um teste ainda hoje com 10 prompts reais e o método T.E.L.A. Se o filtro falhar, ótimo. Você descobriu cedo. Pior é descobrir depois do print.
Fontes que eu realmente li para este artigo: o anúncio e a discussão no X sobre o Rampart, o README do repositório, o whitepaper e a entrevista da equipe no TBPN.