Hoje de manhã eu li uma fala do Alex Karp dizendo que alguns clientes do governo dos Estados Unidos já migraram para modelos abertos. No mesmo pedaço do dia, eu conferi duas peças da infraestrutura que empurram essa conversa: o Ollama estava com 175.359 estrelas no GitHub, e o vLLM com 85.253. Quando a base cresce assim, eu paro de tratar o assunto como hobby de laboratório.
Hoje de manhã eu li uma fala do Alex Karp dizendo que alguns clientes do governo dos Estados Unidos já migraram para modelos abertos. No mesmo pedaço do dia, eu conferi duas peças da infraestrutura que empurram essa conversa: o Ollama estava com 175.359 estrelas no GitHub, e o vLLM com 85.253. Quando a base cresce assim, eu paro de tratar o assunto como hobby de laboratório.
Se você lidera uma empresa, a pergunta não é se open source é moda ou religião. A pergunta útil é outra: quando vale trocar parte da dependência de API por uma stack que eu controlo mais?
TL;DR
Eu não troco API por modelo aberto porque ficou bonito no X. Eu troco quando margem, controle e risco começam a pesar mais do que conveniência.
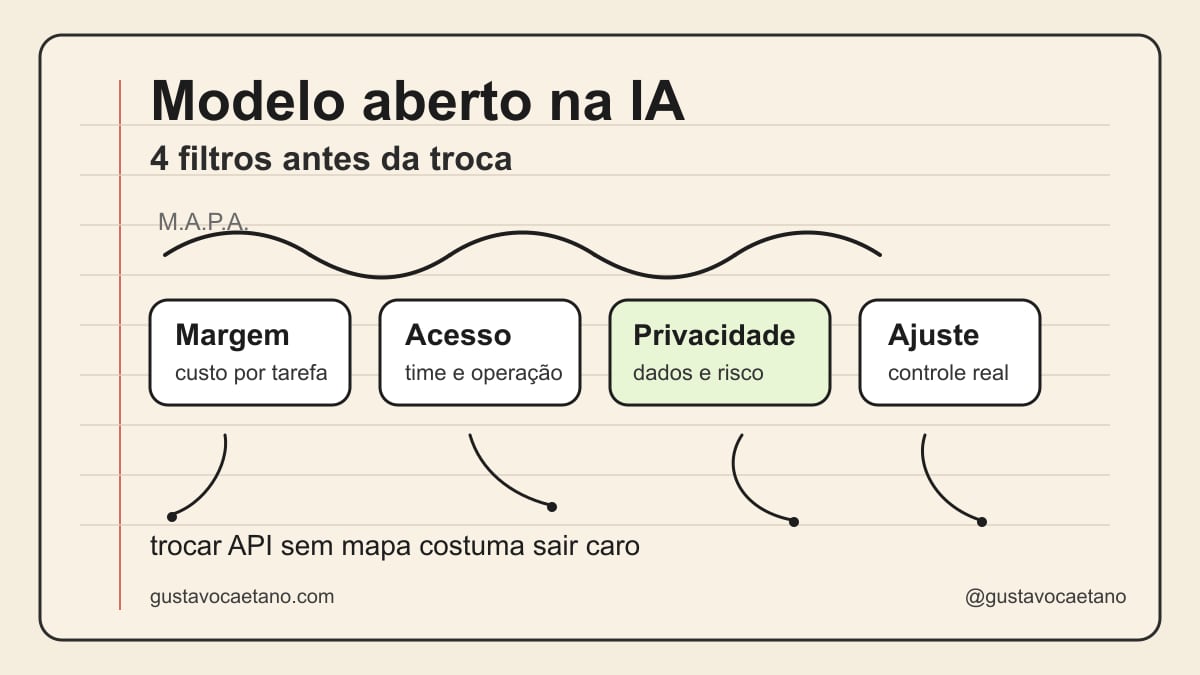
Eu uso o método M.A.P.A. para decidir: Margem, Acesso, Privacidade e Ajuste.
Em vez de migrar tudo, eu começo com um piloto pequeno, medido e com dono. Drama de infraestrutura é caro. Ego técnico também.
O problema
Eu vejo muita empresa comprando IA do jeito errado.
Primeiro, ela assina uma API porque é o caminho mais rápido. Isso faz sentido. Rapidez conta.
Depois, o uso cresce. A conta sobe. O time quer mais controle. A área jurídica começa a perguntar para onde os dados estão indo. O time técnico pede liberdade para testar outros modelos. E o que era uma escolha prática vira dependência.
É aqui que o debate sobre modelo aberto entra.
Não porque “aberto” seja moralmente superior. Isso é balela de torcida. Ele entra porque algumas empresas chegaram num ponto em que conveniência já não compensa sozinha.
O próprio site do Ollama martela uma promessa simples: rodar apps e agentes com modelos abertos e até operar offline. A documentação do vLLM mostra outra parte do jogo: serving, monitoramento, cache, batch, structured outputs e outras peças de operação séria. Ou seja: a pilha aberta deixou de ser só demo de hacker sem sono.
Mas eu também não compro a fantasia oposta.
Modelo aberto não é atalho mágico para ficar barato, privado e maravilhoso ao mesmo tempo. Se o seu time não consegue operar a stack, você só trocou um boleto previsível por uma dor de cabeça com GPU, observabilidade e incidente às 2 da manhã. A nuvem não some porque você ficou corajoso no LinkedIn.
O método M.A.P.A.
Quando eu preciso decidir se um modelo aberto merece piloto, eu uso um filtro simples. Chamo de M.A.P.A. porque founder precisa de critério, não de poesia.
1. Margem
Eu começo pela conta.
Quanto eu gasto hoje com a API? Esse custo varia com volume, contexto longo, picos de uso ou retrabalho? Se eu trocar parte da operação por um modelo aberto, eu ganho margem real ou só mudo a linha da despesa?
Na prática, eu comparo três coisas:
1. custo atual por tarefa útil; 2. custo da operação aberta com hospedagem, suporte e manutenção; 3. custo do erro, porque modelo barato que responde errado cobra juros escondidos.
Se a sua empresa ainda está usando IA em poucos fluxos e com baixo volume, eu quase sempre prefiro a API. Você paga mais por token e compra velocidade.
Se o uso virou rotina de vendas, suporte, busca interna, agentes ou processamento em escala, aí eu paro para simular. Nesse ponto, margem começa a conversar com arquitetura.
2. Acesso
Depois eu olho para a capacidade real do time.
Quem vai subir isso? Quem vai monitorar? Quem vai trocar modelo? Quem vai cuidar de latência, fila, fallback e segurança?
Muita empresa fala “vamos para open source” quando, na prática, ela quer só negociar melhor com o fornecedor atual. Isso já é um uso legítimo da discussão. O problema é confundir desejo de barganha com capacidade operacional.
Se eu não tenho gente para operar o básico, eu não migro o core. Eu faço um piloto em um fluxo secundário. O time aprende. A fumaça baixa. A decisão melhora.
Open source sem dono vira projeto de sexta-feira. E projeto de sexta-feira costuma morrer na terça.
3. Privacidade
Aqui o founder costuma finalmente prestar atenção.
Se eu lido com dado sensível, contrato, financeiro, jurídico, saúde ou informação estratégica, o tema muda de tom. Não é só custo. É exposição.
No Ollama, a promessa de rodar offline e manter o dado sob mais controle faz sentido em alguns casos. Não resolve tudo. Mas muda a conversa.
Eu gosto de fazer três perguntas duras aqui:
esse dado sai do meu ambiente sem problema?
eu preciso registrar tudo para auditoria?
eu consigo limitar bem quem vê, quem consulta e quem exporta?
Se a resposta incomoda, modelo aberto vira menos capricho técnico e mais política de risco.
4. Ajuste
O último filtro é o que separa curiosidade de estratégia.
Eu preciso só de um modelo que responda bem, ou eu preciso de mais controle sobre comportamento, velocidade, contexto, integração e formato de saída?
A documentação do vLLM deixa claro que o jogo não é só “rodar um modelo”. Existe serving online, batch, cache de prefixo, structured outputs, observabilidade e vários caminhos para adaptar a operação ao que a empresa precisa. Isso importa quando IA deixa de ser brinquedo de prompt e vira parte do processo.
Se eu preciso trocar de modelo rápido, testar fornecedor, padronizar saída, integrar agente e mexer em custo com mais liberdade, o ajuste da pilha aberta pesa.
Se eu só quero um assistente bom para o time escrever melhor, eu não invento moda. A melhor arquitetura do mundo também consegue desperdiçar tempo com elegância.
Como aplicar hoje
Se eu tivesse que testar isso hoje, eu faria assim.
Passo 1: escolher um fluxo chato e repetido
Eu não começaria pelo processo mais crítico da empresa. Eu pegaria um fluxo previsível: busca interna, triagem de tickets, resumo de reunião, classificação de documentos ou um agente simples.
Passo 2: montar uma planilha de comparação
Eu abriria quatro colunas:
API atual
modelo aberto hospedado por terceiro
modelo aberto com operação própria
decisão provisória
Em cada linha, eu colocaria custo, latência, privacidade, esforço do time e risco de erro. Sem planilha, a conversa vira torcida com benchmark de café.
Passo 3: definir um piloto de 7 dias
Eu escolheria uma tarefa. Depois nomearia um responsável. Na sequência, eu definiria a régua de sucesso.
Exemplo: “resumir 100 reuniões internas com qualidade aceitável, custo controlado e log completo”. Não vale piloto vago. Vago é o nome bonito do fracasso adiado.
Passo 4: ligar o resto da pilha só quando fizer sentido
Se você ainda está organizando contexto e base de conhecimento, eu recomendo ler também meus textos sobre <a href="/blog/o-que-e-contexto-da-ia">contexto da IA</a>, <a href="/blog/o-que-e-rag-na-ia">RAG</a> e <a href="/blog/o-que-e-mcp-na-ia">MCP</a>. Modelo aberto sozinho não salva processo bagunçado. Ele só bagunça com mais autonomia.
Passo 5: tomar uma decisão pequena
No fim de 7 dias, eu não tentaria decidir o futuro da empresa inteira. Eu responderia só uma pergunta: qual parte da minha operação merece um segundo teste com stack aberta?
Isso já coloca a discussão em outro nível.
Resultados esperados
Eu não espero milagre no primeiro piloto.
O resultado bom da primeira semana é este:
eu descubro se existe ganho real de margem ou só curiosidade técnica;
eu entendo se meu time tem acesso para operar algo além da API pronta;
eu separo privacidade séria de medo genérico;
eu vejo onde ajuste e controle realmente importam.
Se o piloto funcionar, eu ganho clareza para negociar melhor, migrar uma parte da carga ou seguir na API sem culpa. Isso também é vitória.
Decisão boa não é a que parece mais avançada no palco. É a que fecha a conta sem explodir a operação depois.
Perguntas rápidas
Modelo aberto na IA é sempre mais barato?
Não.
Às vezes ele fica mais barato em volume alto ou em fluxos bem definidos. Em outros casos, a conta volta como infraestrutura, suporte, monitoramento e retrabalho. Eu só acredito depois da planilha e do piloto.
Eu preciso rodar tudo local?
Não.
Eu posso usar modelo aberto hospedado por terceiros, operar parte da stack e manter outra parte via API. A decisão não precisa ser ideológica.
Modelo aberto é melhor para privacidade?
Em alguns casos, sim.
Se eu consigo rodar em ambiente controlado, limitar acesso e registrar uso, eu ganho opções melhores. Mas privacidade ruim com modelo aberto continua sendo privacidade ruim. Trocar a tecnologia não absolve processo frouxo.
Onde RAG e MCP entram nisso?
Eles entram quando eu preciso contexto e integração.
Modelo aberto responde. RAG ajuda a buscar a informação certa antes da resposta. MCP ajuda a IA a conversar com ferramentas e sistemas. Uma coisa não substitui a outra.
Quando eu não devo mexer nisso agora?
Quando meu problema ainda é adoção básica.
Se o time mal usa a API atual, eu não começo por open source. Eu começo por caso de uso, processo, dono e resultado. Arquitetura sem uso é coleção cara de boas intenções.
Conclusão
Eu gosto de modelo aberto quando ele resolve uma dor concreta.
Eu não gosto quando ele vira fantasia de independência para empresa que ainda nem decidiu o que quer automatizar.
Se eu precisasse resumir tudo em uma linha, seria esta: open source na IA não é troféu técnico. É uma decisão de margem, controle e risco.
Se você quiser, eu posso levar esse debate para o seu time com exemplos práticos de onde API pronta faz sentido e onde stack aberta começa a ganhar o jogo. A conversa certa não é “qual modelo está bombando?”. A conversa certa é “qual arquitetura me dá resultado sem me prender amanhã?”.