Agentes de IA em 4 testes antes do piloto caro TL;DR Eu uso 4 testes para saber se um agente de IA merece piloto: resultado, evidência, guardrail e recompensa. Eu não confio em demo bonita. Confio em recompensa clara, erro medido e decisão de negócio.
Agentes de IA em 4 testes antes do piloto caro
TL;DR
- Eu uso 4 testes para saber se um agente de IA merece piloto: resultado, evidência, guardrail e recompensa.
- Eu não confio em demo bonita. Confio em recompensa clara, erro medido e decisão de negócio.
- Eu vejo RULER e OpenPipe ART como sinal técnico forte, mas a empresa pode começar com planilha e ChatGPT.
O problema
Eu vejo a mesma cena em muita empresa: alguém mostra um agente de IA respondendo e-mail, puxando dado do CRM e montando relatório em 40 segundos.
A sala sorri. O CFO fica quieto.
Ele sabe o que quase ninguém quer perguntar: "quanto custa quando isso erra?".
No dia 19 de junho de 2026, um post do @akshay_pachaar viralizou falando de RULER, GRPO, junto de um agente Qwen3 1.4B aprendendo a jogar 2048. O ponto não era o jogo. Era o agente receber uma recompensa em linguagem natural para melhorar com tentativa, erro, mais feedback.
O repositório OpenPipe ART já aparecia com cerca de 10,1 mil estrelas no GitHub. O README descreve o ART como um framework open-source para treinar agentes multi-etapa com GRPO.
Traduzindo: a turma técnica está saindo do "prompt esperto" e indo para "agente que aprende por métrica".
Eu acho ótimo. Também acho perigoso.
Porque executivo brasileiro adora pular da demo para o piloto caro. Aí descobre tarde demais que o agente não tinha placar, limite, auditoria nem dono.
Agente de IA sem métrica é estagiário com cartão corporativo. Talvez seja brilhante. Talvez compre passagem para Marte.
Se você ainda está montando a base, leia também Agentes de IA nas empresas. Aqui eu vou para o teste antes do cheque.
O framework / método
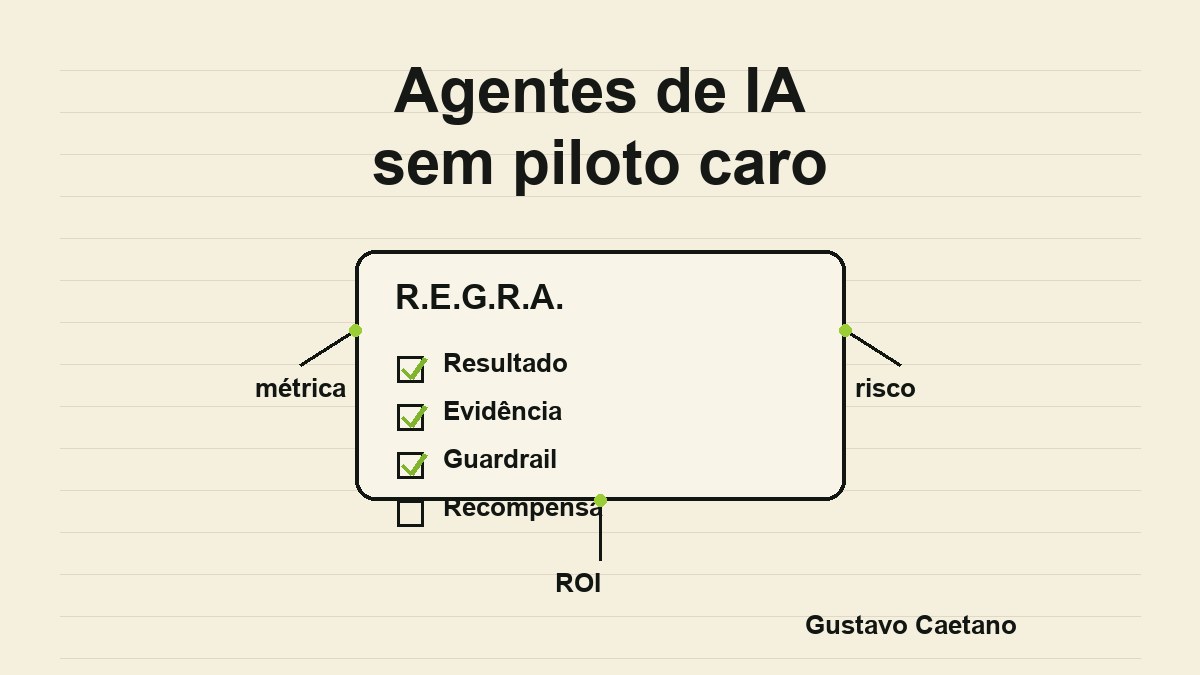
Eu uso o framework R.E.G.R.A. antes de aprovar qualquer piloto de agente.
Resultado. Evidência. Guardrail. Recompensa. Aprendizado.
Os 4 testes são os quatro primeiros. O aprendizado é o que decide se eu continuo, limito ou mato o piloto.
Parece simples porque precisa ser simples. Se o CEO não consegue explicar o teste em 2 minutos, o time técnico vai vender fumaça com dashboard bonito.
1. Resultado: eu defino o placar antes da demo
Eu começo perguntando: "qual número precisa mudar para eu chamar isso de bom?".
Não aceito "ganhar produtividade". Isso é frase de slide.
Eu aceito coisas como:
- reduzir tempo médio de resposta de 8 horas para 2 horas;
- aumentar conversão de lead qualificado de 12% para 15%;
- cortar retrabalho de proposta em 30%;
- reduzir tickets reabertos de 18% para 12%.
Se o agente vai jogar 2048, o placar é claro: pontuação, movimentos ruins, vitórias. Se vai vender, atender ou cobrar, eu preciso do mesmo tipo de placar.
Antes de comprar ferramenta, eu escrevo uma frase:
"O agente será aprovado se melhorar X em Y dias sem piorar Z."
Essa frase salva dinheiro.
2. Evidência: eu separo acerto real de teatro
Eu já errei aqui. Vi agente acertar 5 exemplos escolhidos a dedo e achei que estava pronto.
Não estava.
Hoje eu monto uma tabela com 30 a 100 casos reais. Pequena, chata e honesta.
Eu coloco caso fácil, caso ambíguo, caso incompleto e caso que exige dizer "não sei". Esse último é maravilhoso, porque agente bajulador odeia admitir limite.
Depois eu comparo:
- resposta do humano;
- resposta do agente;
- nota de qualidade;
- risco do erro;
- custo do erro.
Se o agente só funciona nos casos bonitos, eu não tenho piloto. Tenho show de mágica.
E mágica é péssima categoria de investimento.
3. Guardrail: eu decido onde o agente deve parar
Eu não pergunto só quais ações o agente executa. Eu pergunto onde ele deve travar.
Ele sugere desconto? Envia e-mail? Atualiza CRM? Fala com cliente irritado? Promete prazo? Mexe em contrato?
Cada "sim" aumenta o valor possível e o risco possível.
Por isso eu crio três faixas:
- verde: o agente executa sozinho;
- amarelo: o agente rascunha e pede revisão;
- vermelho: o agente bloqueia e chama humano.
Um exemplo simples: responder dúvida sobre horário de atendimento é verde. Dar desconto fora da política é vermelho. Escrever retorno comercial fica no amarelo.
O piloto caro nasce quando a empresa pula essa conversa e chama tudo de autonomia.
Autonomia sem limite é aposta. Às vezes dá certo. Normalmente vira reunião de crise.
4. Recompensa: eu ensino o agente com linguagem de negócio
Aqui entra o sinal técnico do dia.
O RULER, citado pelo OpenPipe, aponta para uma ideia poderosa: usar linguagem natural para avaliar se a trajetória do agente foi boa. O ART organiza o treino com simulações, trajetórias, além de uma recompensa no fim da execução.
Eu gosto disso porque aproxima o treino do jeito que empresa pensa.
Nem toda recompensa precisa começar como fórmula matemática perfeita. Ela pode começar como rubrica:
- resolveu o problema do cliente;
- não inventou dado;
- seguiu a política comercial;
- pediu humano quando havia risco;
- registrou o motivo da decisão.
Depois eu transformo essa rubrica em nota de 0 a 5.
Se o agente ganha ponto por resolver rápido, ele vai tentar ser rápido. Se ganha ponto por resolver rápido e sem inventar, ele começa a aprender o jogo certo.
É igual comissão de vendedor. Se você paga só por contrato assinado, não reclame quando aparece venda ruim. O incentivo ensinou a pessoa.
Com agente, a recompensa ensina a máquina.
5. Aprendizado: eu exijo melhora em ciclos curtos
Um piloto de agente não serve para provar que IA existe. Isso eu já sei.
Ele serve para provar que o sistema aprende.
Eu separo ciclos semanais. Em cada ciclo, eu quero ver:
- erros mais frequentes;
- nova regra ou novo exemplo criado;
- melhoria na nota média;
- redução dos erros graves;
- decisão clara de continuar, limitar ou matar o piloto.
Se depois de 3 semanas o agente continua errando igual, eu não chamo de aprendizado. Chamo de assinatura mensal com autoestima.
Para medir melhor esse lado executivo, eu recomendo também Como medir se a IA está melhorando a empresa.
Como aplicar hoje
Eu começaria sem GPU, sem fine-tuning e sem comitê de 12 pessoas.
Abra uma planilha.
Crie estas colunas:
- caso real;
- resposta humana esperada;
- resposta do agente;
- resultado de negócio;
- risco se errar;
- nota de 0 a 5;
- motivo da nota;
- regra nova aprendida.
Pegue 30 casos do seu processo. Atendimento, SDR, cobrança, proposta, suporte interno, jurídico simples, triagem de vaga. Escolha um.
Depois rode cada caso no ChatGPT ou Claude com o mesmo prompt. Não fique melhorando prompt no meio do teste, senão você estraga a comparação.
Use esta rubrica:
Avalie a resposta do agente de 0 a 5. 5 = resolveu o caso, usou dados corretos, respeitou a regra e não criou risco.
4 = resolveu o caso com pequeno ajuste humano.
3 = ajudou, mas deixou ponto importante faltando.
2 = respondeu algo parcialmente errado ou arriscado.
1 = errou o objetivo principal.
0 = inventou informação, violou regra ou deveria ter chamado humano. Explique a nota em uma frase curta.Eu gosto de pedir uma segunda avaliação para outro modelo. Por exemplo: Claude responde, ChatGPT julga. Ou o contrário.
Isso não é ciência perfeita. É triagem executiva.
Se quiser ir para o lado técnico, aí faz sentido olhar OpenPipe ART, RULER e GRPO. O ART permite treinar agentes multi-etapa com trajetórias e recompensa. Mas eu só iria para esse caminho depois de provar que a rubrica faz sentido.
Minha regra: planilha antes de GPU.
Se a planilha não mostra valor, o cluster só vai deixar o prejuízo mais caro.
Para desenhar um piloto que o financeiro não odeie, veja também Piloto de IA que o CFO aprova.
Resultados esperados
Eu esperaria 3 tipos de resultado em 2 a 4 semanas.
O primeiro é clareza. Em 30 casos reais, normalmente eu já descubro se o agente é promessa séria ou brinquedo caro.
O segundo é economia. Em processos de texto repetitivo, eu costumo mirar 20% a 40% de redução de tempo no fluxo assistido, não no fluxo 100% autônomo.
O terceiro é corte de risco. Eu prefiro um agente que automatiza 60% com erro baixo do que um que tenta 100% e cria bomba escondida.
Um exemplo:
Se um time gasta 200 horas por mês em triagem comercial, uma redução de 30% libera 60 horas. Se a hora carregada custa R$ 120, isso dá R$ 7.200 por mês de capacidade recuperada.
Não é manchete de unicórnio. É conta.
Agora compare isso com um piloto de R$ 80 mil sem métrica. O agente precisa entregar mais de 11 meses desse ganho só para empatar, antes de contar manutenção, revisão e erro.
É por isso que eu gosto dos 4 testes. Eles matam o oba-oba cedo.
FAQ
Eu preciso usar OpenPipe ART para testar agentes?
Não. Eu começaria com planilha, casos reais e ChatGPT ou Claude.
Eu usaria OpenPipe ART quando já tivesse processo claro, rubrica boa e volume suficiente para treinar de verdade.
RULER substitui avaliação humana?
Eu não trataria assim.
Eu vejo RULER como uma forma de transformar critério humano em recompensa mais escalável. No começo, eu ainda quero humano auditando amostra, principalmente nos erros caros.
GRPO é assunto para CEO?
O nome técnico, não.
A lógica, sim: o agente tenta, recebe recompensa, melhora. O CEO precisa entender o mecanismo para não comprar "agente inteligente" sem saber como ele aprende.
Qual processo eu testaria primeiro?
Eu escolheria processo com volume alto, regra clara e erro reversível.
Triagem de lead, resumo de atendimento, classificação de ticket e preparação de reunião são bons candidatos. Negociação sensível, contrato e crise com cliente ficam para depois.
Quando eu mato o piloto?
Eu mato quando o agente não melhora depois de ciclos curtos, quando o erro grave continua aparecendo ou quando o ganho financeiro depende de uma hipótese heroica.
Piloto bom também serve para dizer "não".
Conclusão
Eu gosto de agentes de IA. Gosto mais ainda quando eles passam por teste chato.
O post viral sobre RULER, ART, GRPO e Qwen3 1.4B aprendendo 2048 mostra uma direção clara: agente bom vai ser treinado com recompensa, não só com prompt bonito.
Mas a sua empresa não precisa começar no laboratório.
Comece com 30 casos reais, uma planilha, uma rubrica simples e quatro testes: resultado, evidência, guardrail e recompensa. Depois rode o ciclo de aprendizado. Ou ele aparece, ou você mata cedo.
Meu CTA é direto: antes de aprovar o próximo piloto caro de agente, faça a R.E.G.R.A. em uma tarde.
Se passar, você sai com um piloto defensável.
Se falhar, você acabou de economizar dinheiro e reunião.